Backup and Restore
Katonic Platform cluster Backup
Prerequisites:
You should have access to your Kubernetes cluster as a requirement.
You must configure bucket storage with the appropriate access privileges (get, update, delete, write, etc.) on your preferred cloud provider.
If you are using AWS, you can create an S3 bucket by accessing Amazon Simple Storage Service. This will enable you to store and retrieve data easily. Create your first S3 Bucket - Amazon Simple Storage Service.
If you are using Azure, you can generate Blob storage by setting up a storage account within the same resource group as your AKS cluster. This will allow you to store and manage unstructured data efficiently. Create a Storage Account - Azure Storage.
If you are using GCP, you can create a GCS bucket (Google Cloud Storage) to store your data. This will provide you with a scalable and durable storage solution within the Google Cloud Platform ecosystem. To Create GCP GCS buckets.
Remember to configure the storage options according to your specific requirements and integrate them seamlessly with your Kubernetes cluster.
A minimum of 2 compute nodes are required to enable backup. Therefore, when backup_enabled = True, then compute_nodes.min_count should be set to 2.
Steps to take a backup of the Katonic platform cluster:
Download the backup script by executing the following command:
curl -O https://raw.githubusercontent.com/katonic-dev/Platform-Migration/master/katonic-platform-backup-4-5.shGrant the script execute permission with the following command:
chmod +x katonic-platform-backup-4-5.shExecute the backup script using the following command:
./katonic-platform-backup-4-5.shNote: Please ensure that you use this prescribed method and refrain from using any alternative approaches for taking the backup.
To restore the Katonic platform cluster on the new vanilla cluster.
Install the Velero tool on your local machine and cluster by executing the installation scripts provided.
curl -O https://raw.githubusercontent.com/katonic-dev/Platform-Migration/master/katonic-platform-4-5-restore-1.sh
chmod +x katonic-platform-4-5-restore-1.shIf you have previously installed Velero on your local machine and cluster, ensure that you know the name of the bucket from which you want to restore the cluster.
./katonic-platform-4-5-restore-1.shNote: Please ensure that you use this prescribed method and refrain from using any alternative approaches for taking the backup.
Note: Restore Procedure in Azure
When you run the restore script, a job named
velero-restoreis created. This job generates a Kubernetes pod in the default namespace.In the case of Azure, it's essential to monitor the logs of the
velero-restorepod using the following command, and manually login into your azure account.kubectl logs -f job/velero-restore
If the bucket name is different, delete the Velero namespace and run the restore script, "katonic-platform-4-5-restore-1.sh", again. When executing the script, select 'no' when prompted if Velero is already installed in your cluster, and provide the necessary parameters to correctly install Velero.
velero get backup-locationTo monitor the progress of the restore process and check which namespaces have been restored or are still pending, use the following command:
watch velero get restoreOnce the backup has been fully restored, i.e., the execution of "katonic-platform-4-5-restore-1.sh" is completed successfully, you can run "katonic-platform-4-5-restore-2.sh" to delete the temporary pods created during the restore process.
curl -O https://raw.githubusercontent.com/katonic-dev/Platform-Migration/master/katonic-platform-4-5-restore-2.sh
chmod +x katonic-platform-4-5-restore-2.sh
./katonic-platform-4-5-restore-2.sh
Troubleshooting
Run this Patch command (For pipeline cache issue).
kubectl patch mutatingwebhookconfiguration cache-webhook-kubeflow --type='json' -p='[{"op":"replace", "path": "/webhooks/0/rules/0/operations/0", "value": "DELETE"}]'Rollout restart the
miniostatefulset andminio-consoledeployment.kubectl rollout restart sts minio
kubectl rollout status sts minio
kubectl rollout restart deploy minio-console
kubectl rollout status deploy minio-consoleRollout restart all deployments from the kubeflow namespace.
kubectl rollout restart deploy -n kubeflowmongo-db-mongodbStatefulSet pod crashloopbackupoff.mongo-db-mongodbStatefulSet have 2 replicas.
The reason might be corrupt data. While backing up the application namespace. Data might be not backup properly. That’s why mongo-db-mongodb StatefulSets 1 pod goes in crashloopbackoff status.
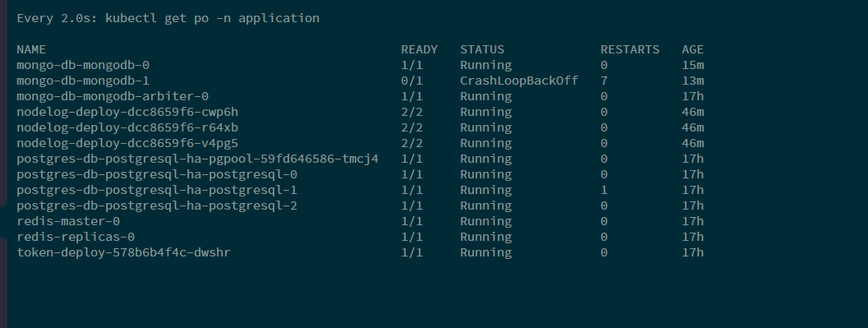
Solution:
Scale down the
mongo-db-mongodbStatefulSet to 0.kubectl scale sts mongo-db-mongodb -n application --replicas=0Delete the PVC of that crashloopbackoff pod only. (Don’t delete another PVC. Just that crashloopbackoff pod PVC. If you delete the other pod PVC then all data of
mongo-db-mongodbStatefulSet will be deleted.)kubectl delete pvc <crashloopbackoff-pod-pvc-name-only> -n application
Scale up the
mongo-db-mongodbStatefulSet to 2.kubectl scale sts mongo-db-mongodb -n application --replicas=2
The
mongo-db-mongodbStatefulSet pod crashloopbackoff might come inmlflow-postgres-postgresql-ha-postgresqlStatefulSet.Solution: Do the same process of
mongo-db-mongodbStatefulSet(Troubleshoot no. 5).New user is created but that user workspace is not created then check the private and shared PVC of that user namespace. If the PVCs are not there then, the issue is the DLF Plugin "dataset-operator" is misbehaving.
Solution: Restarted the
dataset-operator.kubectl rollout restart deployment dataset-operator -n dlfIf you are getting 500 or 502 error then take access of your cluster and run the below command for restarting
nodelog-deploydeployment in the application namespace.kubectl rollout restart deploy nodelog-deploy -n application